はじめに
最近になって日本高配当株を少しづつ買うようになりました。
投資信託しか買った経験がありませんでしたので、自分でポートフォリオを考えるのも初めてです。
高配当株について勉強した結果と楽天証券から取得したデータをpythonで見える化してみました。
高配当株とは?メリット/デメリット
高配当株とは
配当利回りが市場平均を上回る企業の株式のことです。配当利回りは以下の式で計算されます。
配当利回り(%) = (年間配当金 ÷ 株価) * 100
一般に配当利回りが3~5%以上の株を「高配当株」と呼びます。高配当株は成熟した業界で安定した収益を上げている企業に多く見られます。これらの企業は成長余地が限られている為、利益の多くを株主に還元する傾向があります。
高配当株のメリット
高配当株の最大の魅力は、安定した配当収入を得られる点です。株価の変動にかかわらず、定期的に配当金が支払われるため、キャッシュフローを確保したい投資家にとって理想的な選択肢です。特に、老後の安定した収入源を確保したい場合に有効です。
株価の下落リスクに対するヘッジ
高配当株は、一般的にディフェンシブ銘柄が多く、景気の変動に強いとされています。株価が大きく下がる局面でも、配当金を期待できるため、下落リスクの一部を補うことができます。ただし、業績悪化による減配リスクがゼロというわけではないのでそれ相応の対策が必要です。
再投資による複利効果
配当金をそのまま再投資することで、複利効果を得ることができます。特に長期投資では、配当金を使ってさらに株を買い増しすることで、次の配当額が増え、雪だるま式に資産が増えていくという効果が期待できます。ただし、配当金に税金がかかることには注意が必要です。NISAを利用すれば非課税で運用することができます。
高配当株ポートフォリオ
分散投資
高配当株を選ぶ際には、業種(セクター)の分散が重要です。同じセクターの株ばかりを購入すると、業界全体が不調になったときにポートフォリオ全体が打撃を受けてしまうため、複数のセクターに分散投資することがリスクヘッジになります。なお、東証では33のセクターに分けられています。
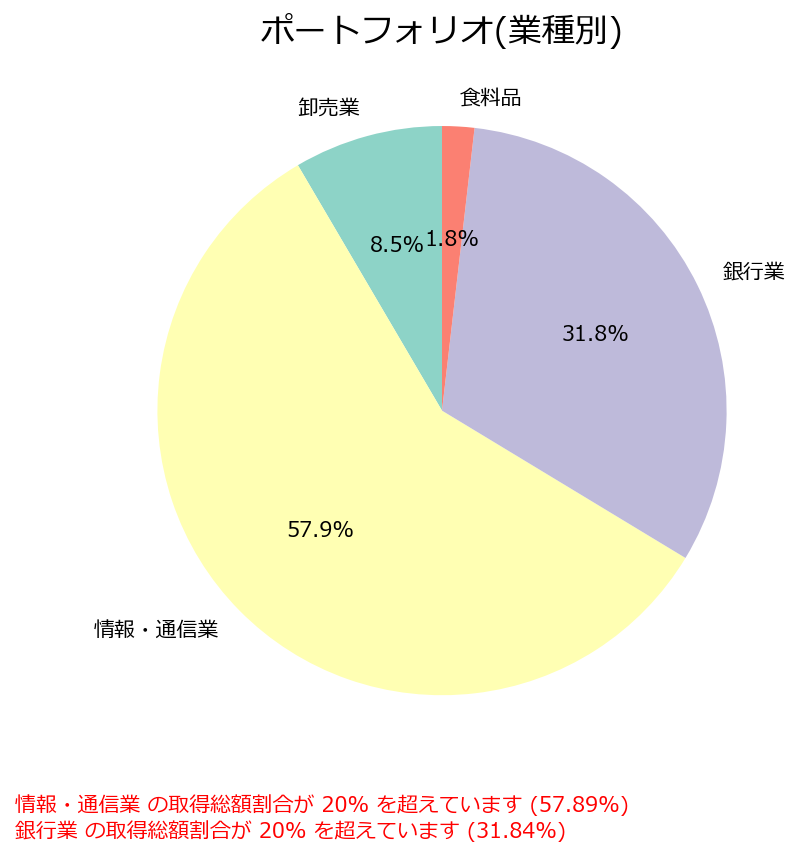
ポートフォリオを組む際は、1つのセクターが多くても20%未満となるようにするのが安心です。
配当金の割合
全体の配当金に対して、特定の1社が占める極端に大きいと、スキャンダルなどでその企業だけが不振になっただけでも得られる配当が大きく減少してしまいます。
ポートフォリオを組む際は、配当金が全体の配当金の3%未満となるようにするのが安心です。
ポートフォリオの見える化(楽天証券)
楽天証券から取得したデータをpythonでセクター毎の円グラフにできるコードです。
以下の様なグラフが出力できます。
自身の保有株は以下の様にしてDLすることができます。
企業名と業界(セクター)のベースデータは以下です。上記csvと合体(マージ)して使います。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 日本語フォントの設定(例: Windows環境では "Meiryo" が一般的)
plt.rcParams['font.family'] = 'Meiryo'
#自身のフォルダ名とファイル名。フォルダにはdata_j.xlsとcsvファイルの両方を格納
folder_path = '**************'
file_name = '*************.csv'
#データを銘柄コードでマージする
#所定のデータ行までskiprowsで読み飛ばし。自身のデータに合わせてください
my_data = pd.read_csv(folder_path + file_name, encoding='shift-jis',skiprows=range(6))
my_data=my_data.dropna()
base_data = pd.read_excel(folder_path+'data_j.xls')
base_data=base_data.dropna()
#リネーム
base_data = base_data.rename(columns={'コード':'銘柄コード'})
base_data=base_data.drop('銘柄名',axis=1)
#マージ
my_data = pd.merge(my_data, base_data, on=['銘柄コード'])
#カンマ削除と型変換
my_data['保有数量[株]'] = my_data['保有数量[株]'].map(lambda x: str(x).replace(',', '')).astype(int)
my_data['取得総額[円]'] = my_data['取得総額[円]'].map(lambda x: str(x).replace(',', '')).astype(int)
my_data['33業種コード'] = my_data['33業種コード'].map(lambda x: str(x).replace(',', '')).astype(int)
#集計
sector_data=my_data.groupby('33業種区分')['取得総額[円]'].sum().reset_index()
#グラフ化
# 総額を計算
total_amount = sector_data['取得総額[円]'].sum()
# 各業種の割合を計算
sector_data['割合'] = sector_data['取得総額[円]'] / total_amount * 100
# 警告メッセージを保存するリスト
warnings = []
# 20%を超える割合があった場合、警告を出力し、メッセージを保存
for index, row in sector_data.iterrows():
if row['割合'] > 20:
warning_message = f"{row['33業種区分']} の取得総額割合が 20% を超えています ({row['割合']:.2f}%)"
warnings.append(warning_message)
# 円グラフを作成
plt.figure(figsize=(6, 6))
plt.pie(sector_data['取得総額[円]'], labels=sector_data['33業種区分'], autopct='%1.1f%%', startangle=90, colors=plt.cm.Set3.colors)
# グラフのタイトルを追加
plt.title('ポートフォリオ(業種別)', fontsize=16)
# 警告メッセージをグラフに表示
if warnings:
warning_text = "\n".join(warnings)
plt.text(-1.5, -1.5, warning_text, fontsize=10, color='red', ha='left')
# グラフを表示
plt.show()
コメント